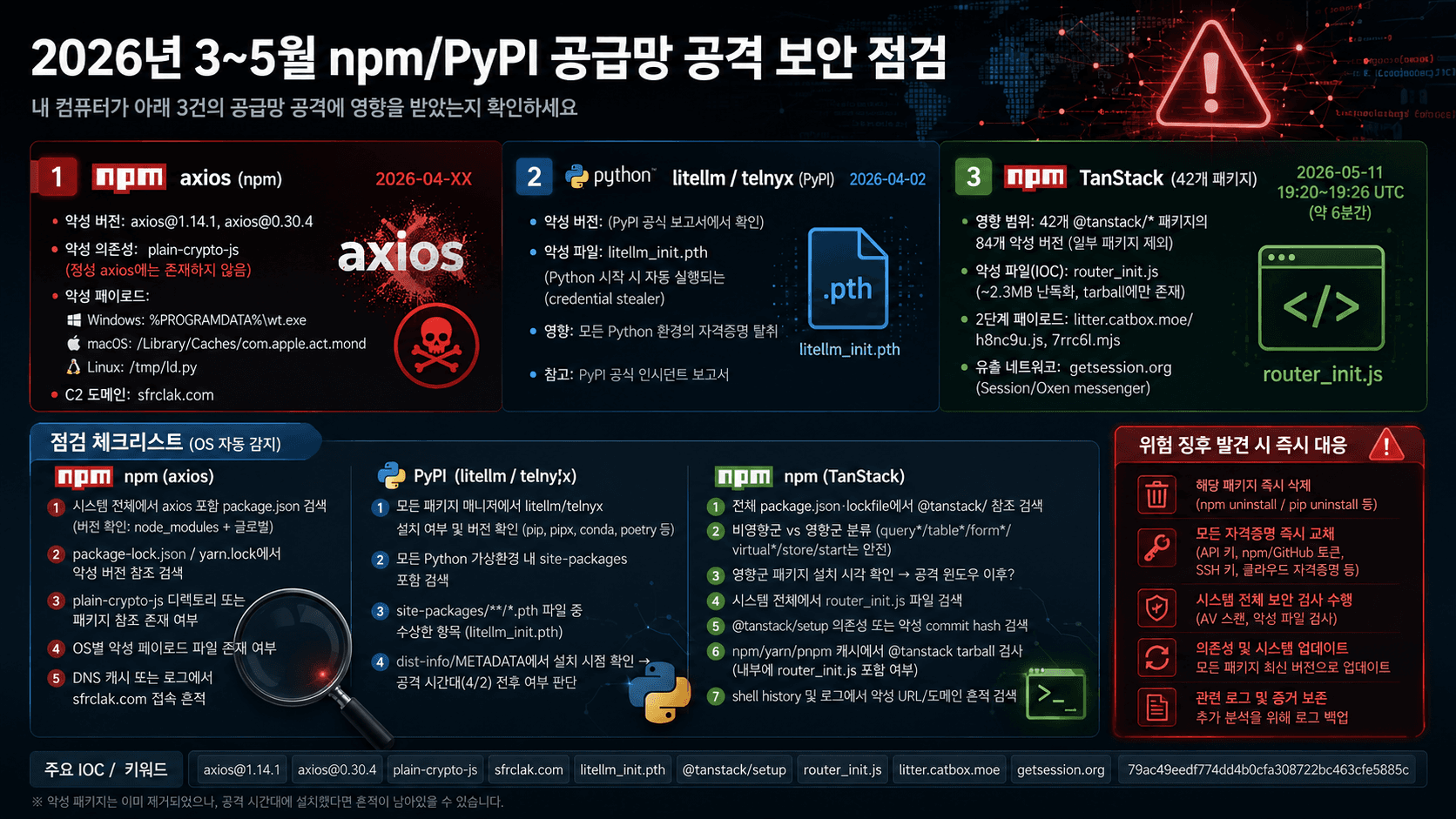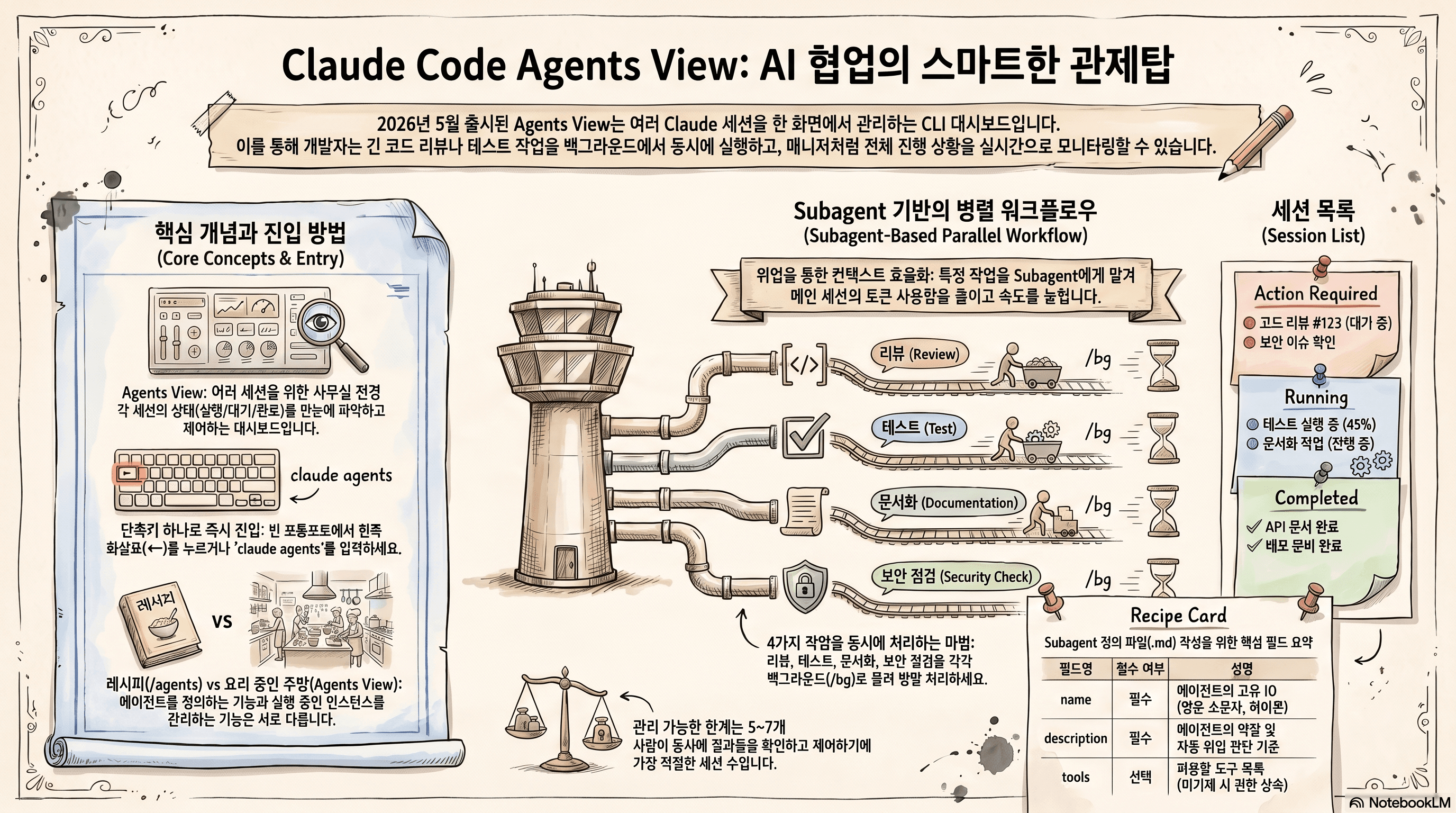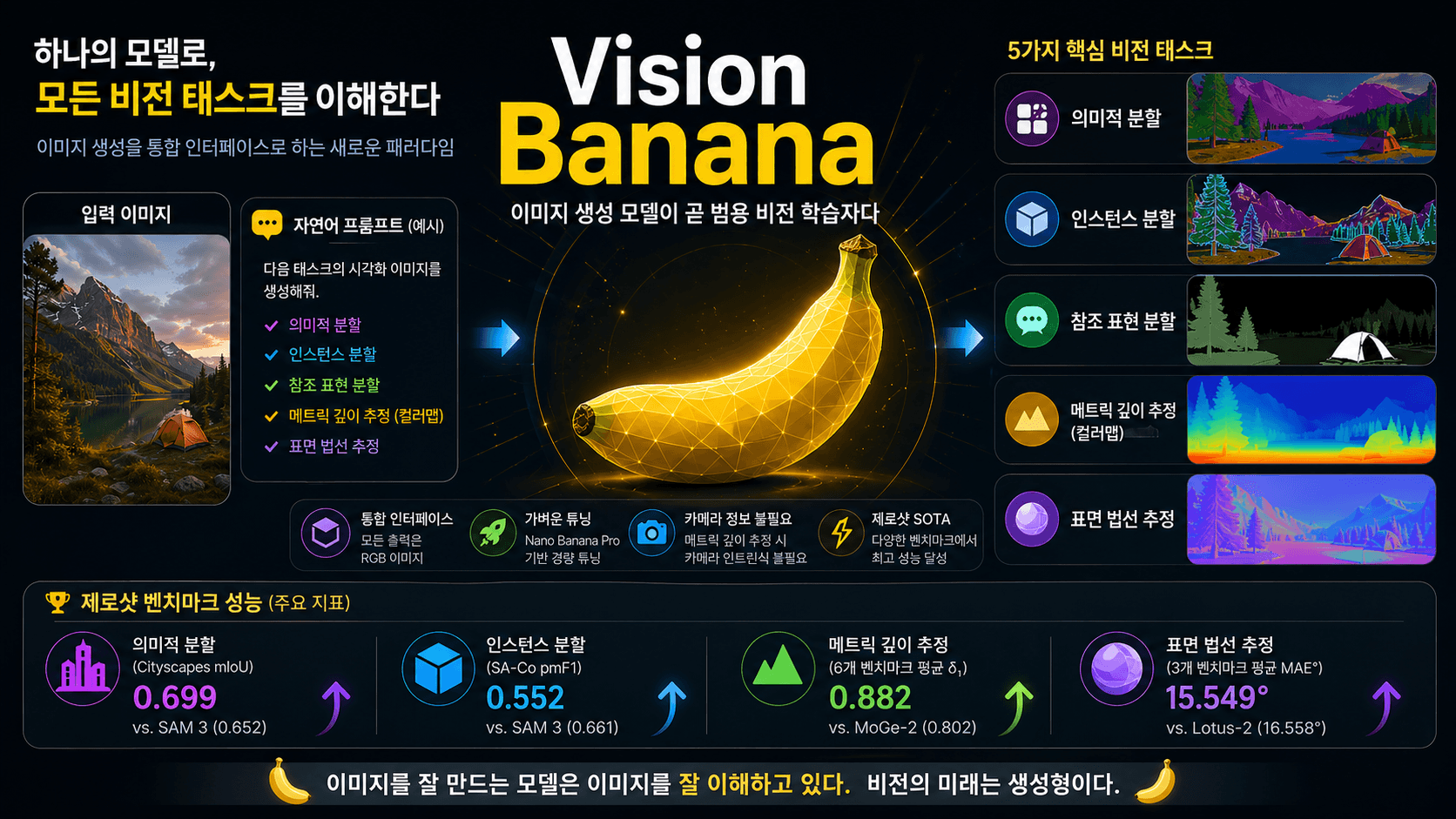
Vision Banana: 이미지 생성 모델이 곧 범용 비전 학습자다
Google DeepMind, 2026년 4월 22일 발표 (arXiv:2604.20329 · 프로젝트 페이지)
TL;DR
- Vision Banana는 Google DeepMind가 공개한 이미지 이해 + 이미지 생성을 통합한 SOTA 모델입니다.
- 핵심 주장은 단순하면서도 대담합니다. "이미지 생성 사전학습은 LLM의 텍스트 사전학습과 동일한 역할을 한다." 즉, 이미지를 잘 만드는 모델은 이미지를 잘 이해하는 모델이기도 하다는 것이죠.
- 비전 태스크의 출력을 RGB 이미지로 파라미터화(parameterize) 하는 방식으로, segmentation·depth·surface normal 같은 인식(perception) 문제를 모두 이미지 생성 문제로 재정의합니다.
- 그 결과 SAM 3, Depth Pro, MoGe-2 같은 도메인 특화 모델들을 zero-shot 환경에서 능가하거나 동등한 수준의 성능을 보여줍니다.
- 베이스 모델은 Nano Banana Pro(NBP) 이며, 가벼운 instruction-tuning만으로 이 결과를 달성했습니다. 기존 이미지 생성 능력도 그대로 유지됩니다.

1. 왜 주목해야 하는가
LLM의 발전 과정을 떠올려 봅시다. GPT 계열 모델은 그저 "다음 토큰을 예측"하는 생성형 사전학습만으로 추론·요약·번역 등 광범위한 언어 이해 능력을 emergent하게 획득했습니다.
비전 분야에서도 오랫동안 비슷한 가설이 있었습니다. "이미지를 만들 줄 안다는 것은 이미지를 이해한다는 의미다." 그러나 지금까지 생성형 비전 모델이 인식 태스크에서 의미 있는 성능을 보여준 사례는 제한적이었습니다.
Vision Banana는 이 가설을 본격적으로 입증한 첫 번째 대규모 결과물입니다. 논문 저자들은 이를 두고 "컴퓨터 비전의 패러다임 전환을 목격하고 있는 것일 수 있다" 고 표현합니다. 생성형 비전 사전학습이 이미지 생성과 이해를 모두 담당하는 Foundational Vision Model의 핵심이 될 수 있다는 주장입니다.
2. 핵심 아이디어: "Perception as Image Generation"
Vision Banana의 접근법은 한 줄로 요약됩니다.
모든 비전 태스크의 출력을 RGB 이미지로 표현하고, 그 이미지를 생성하도록 모델을 instruction-tuning 한다.
예를 들어:
| 태스크 | 기존 방식 | Vision Banana 방식 |
|---|---|---|
| Semantic Segmentation | 픽셀별 클래스 ID 예측 | 클래스별 색상으로 칠해진 RGB 이미지 생성 |
| Depth Estimation | float 형태의 depth map 예측 | rainbow colormap으로 시각화된 depth 이미지 생성 |
| Surface Normal | 3D 벡터 예측 | normal 벡터를 RGB로 인코딩한 이미지 생성 |
| Referring Segmentation | 마스크 + 텍스트 매칭 | "빨간 옷을 입은 사람을 흰색으로 칠한 이미지" 생성 |
프롬프트 예시 (실제 데모에서 발췌·요약):
Generate a visualization image of semantic segmentation, using this color mapping:
{"cat ears": <255, 165, 0>, "exit sign": <0, 0, 255>, "background": <125, 0, 125>}
Predict the metric depth of this scene as an image.
Visualized in the rainbow (black-red-yellow-green-cyan-blue-violet-white) color palette.
LLM에서 텍스트 생성이 모든 언어 태스크의 통합 인터페이스가 된 것처럼, 이미지 생성을 비전 태스크의 통합 인터페이스로 사용하는 발상입니다.
3. 학습 방식
- 베이스 모델: Nano Banana Pro (NBP)
- 학습 방식: Lightweight instruction-tuning
- 데이터 구성: NBP 원래의 학습 데이터 + 소량의 비전 태스크 데이터 혼합
- 유지되는 능력: 베이스 모델의 일반 이미지 생성 능력은 그대로 보존
여기서 중요한 포인트는 "가벼운 인스트럭션 튜닝" 입니다. 도메인 특화 모델을 처음부터 학습한 것이 아니라, 이미 이미지 생성을 잘하는 모델에 적은 양의 비전 태스크 데이터를 추가한 것만으로 SOTA를 달성했다는 점입니다. 이는 곧 베이스의 생성 사전학습 단계에서 이미 풍부한 시각 표현이 학습되어 있었음을 시사합니다.
4. 지원 태스크 (Capabilities)
Vision Banana는 다음 다섯 가지 핵심 비전 태스크를 단일 모델로 처리합니다.
4.1 Semantic Segmentation (의미적 분할)
프롬프트로 클래스별 색상 매핑을 지정하면, 입력 이미지에 대해 픽셀 단위 분할 결과를 RGB 이미지로 생성합니다.
4.2 Instance Segmentation (인스턴스 분할)
"마늘 한 쪽씩 다른 색으로", "농구공마다 다른 색의 원형 마스크로" 같은 자연어 지시만으로 인스턴스 분할이 가능합니다.
4.3 Referring Expression Segmentation (참조 표현 분할)
"분홍 티셔츠를 입은 남자는 흰색, 다른 남자는 초록색" 같은 자연어 묘사로 특정 객체를 지정해 분할할 수 있습니다.
4.4 Monocular Metric Depth Estimation (단안 메트릭 깊이 추정)
단일 이미지에서 metric depth를 추정합니다. 카메라 intrinsic 정보를 학습이나 추론 어디에도 사용하지 않는다는 점이 특히 인상적입니다.
4.5 Surface Normal Estimation (표면 법선 추정)
장면의 표면 법선 맵을 생성합니다.
5. 벤치마크 결과
5.1 2D 이해 (Zero-shot Transfer 기준)
Cityscapes — Semantic Segmentation (mIoU ↑)
| 모델 | mIoU | 비고 |
|---|---|---|
| SegMan-L | 0.842 | Non Zero-Shot |
| APE-D | 0.442 | |
| OpenSeeD | 0.478 | |
| X-Decoder | 0.520 | |
| SAM 3 | 0.652 | |
| Vision Banana 🍌 | 0.699 | Zero-shot SOTA |
SA-Co/Gold — Instance Segmentation (pmF1 ↑)
| 모델 | pmF1 |
|---|---|
| SAM 3 (Non Zero-Shot) | 0.661 |
| APE-D | 0.369 |
| OWLv2 | 0.420 |
| Gemini 2.5 | 0.461 |
| DINO-X | 0.540 |
| Vision Banana 🍌 | 0.552 |
RefCOCOg val (UMD) — cIoU ↑
| 모델 | cIoU | 비고 |
|---|---|---|
| HyperSeg + Phi2 | 0.794 | Non Zero-Shot |
| X-SAM + Phi3 | 0.838 | Non Zero-Shot |
| HybridGL | 0.513 | |
| Kang + LLaVA | 0.677 | |
| SAM 3 + Gemini 2.5 Pro | 0.734 | |
| Vision Banana 🍌 | 0.738 | Zero-shot SOTA |
ReasonSeg val — gIoU ↑
| 모델 | gIoU | 비고 |
|---|---|---|
| X-SAM + Phi3 3.8B | 0.566 | Non Zero-Shot |
| LISA-13B-LLAVA1.5 | 0.650 | Non Zero-Shot |
| SegZero | 0.626 | |
| RSVP + GPT-4o | 0.647 | |
| SAM 3 + Gemini 2.5 Pro | 0.770 | |
| Vision Banana 🍌 + Gemini 2.5 Pro | 0.793 | Zero-shot SOTA |
5.2 3D 이해 (Zero-shot Transfer 기준)
Metric Depth — 6개 벤치마크 평균 (δ₁ ↑)
| 모델 | δ₁ |
|---|---|
| Depth Pro | 0.715 |
| MoGe-2 | 0.802 |
| UniK3D | 0.823 |
| Vision Banana 🍌 | 0.882 |
Vision Banana는 학습/추론 어디에서도 카메라 intrinsic을 사용하지 않습니다.
Surface Normal — 3개 벤치마크 평균 (Mean Angular Error °, ↓)
| 모델 | MAE (°) |
|---|---|
| Marigold | 19.606 |
| StableNormal | 17.168 |
| DSINE | 17.017 |
| Lotus-2 | 16.558 |
| Vision Banana 🍌 | 15.549 |
요약하면, segmentation·metric depth·surface normal 모든 영역에서 zero-shot SOTA를 달성했고, 일부 벤치마크에서는 도메인 특화 학습을 한 모델까지도 압도합니다.
6. 시사점: 왜 우리가 이걸 봐야 하는가
6.1 "Foundational Vision Model"의 시대
지금까지의 비전 분야는 태스크별로 SAM(분할), Depth Pro·MoGe(깊이), DINOv2(표현 학습) 같은 모델이 각자 선두를 다투는 구조였습니다. Vision Banana는 하나의 통합 모델로 이 모든 영역을 zero-shot으로 커버합니다. LLM이 텍스트 분야에서 했던 것과 동일한 통합을 비전에서 시도한 셈입니다.
6.2 인터페이스의 통일
LLM이 강력한 이유 중 하나는 "자연어"라는 단일 인터페이스로 거의 모든 언어 태스크를 표현할 수 있다는 점입니다. Vision Banana는 "RGB 이미지"를 그 통일 인터페이스로 제안합니다. 새로운 태스크가 생겨도 출력을 이미지로 표현할 수만 있다면, 별도의 헤드나 디코더 없이 동일한 모델로 처리 가능합니다.
6.3 사전학습 패러다임의 변화 가능성
비전 분야의 self-supervised pretraining은 그동안 contrastive(SimCLR, MoCo), masked image modeling(MAE, BEiT) 등이 주류였습니다. Vision Banana의 결과는 생성형 사전학습이 그 자체로 강력한 비전 표현 학습 방식임을 보여줍니다. 이는 비전 백본 모델 선택의 기준 자체를 흔들 수 있는 결과입니다.
6.4 실무 관점에서의 함의
- 모델 운영 비용 절감 가능성: 태스크별로 모델을 따로 배포·관리하는 부담이 줄어듭니다.
- 자연어 인터페이스: 비전 엔지니어가 아니어도 프롬프트로 분할/깊이 추정 등을 요청할 수 있습니다.
- 확장성: 새로운 비전 태스크 도입 시 fine-tuning 데이터 부담이 크게 줄어듭니다.
다만 현재 시점에서는 모델 가중치나 API가 공개되지 않은 연구 단계이며, 추론 비용·지연시간이 도메인 특화 모델 대비 어떨지는 별도 검토가 필요합니다.
7. 정리
Vision Banana가 던지는 메시지를 한 문장으로 요약하면 이렇습니다.
"이미지를 잘 만드는 모델은 이미 이미지를 잘 이해하고 있다. 우리는 그 능력을 끌어내기만 하면 된다."
LLM이 텍스트 생성이라는 단일 목표에서 출발해 언어 이해의 모든 것을 아우른 것처럼, 이미지 생성도 비전 이해의 통합 패러다임이 될 수 있습니다. SAM 3, Depth Pro 같은 강력한 특화 모델들이 zero-shot으로 추월당했다는 사실 자체가 이 가설의 강력한 증거입니다.
비전 모델을 다루거나 멀티모달 시스템을 설계하는 분이라면, 향후 1~2년간 "생성형 비전 백본" 이라는 흐름을 주의 깊게 지켜볼 필요가 있겠습니다.
참고 자료
- 프로젝트 페이지: https://vision-banana.github.io
- 논문 (arXiv): https://arxiv.org/abs/2604.20329
- 논문 PDF: https://arxiv.org/pdf/2604.20329
- 발표 기관: Google DeepMind
- 주요 저자(Project Leads): Valentin Gabeur, Shangbang Long, Songyou Peng
BibTeX
@article{visionbanana2026,
title={Image Generators are Generalist Vision Learners},
author={Gabeur, Valentin and Long, Shangbang and Peng, Songyou and others},
journal={arXiv preprint arXiv:2604.20329},
year={2026}
}